Hi. I'm Ryan.
I am a lifelong learner with a passion for data and analytics. I enjoy collaborating with fellow data-driven, creative individuals seeking to solve complex problems using ethical practices.
After achieving my childhood goal of designing buildings professionally, my curious nature has driven me to explore new career challenges that leverage my technical knowledge and analytical capabilities. When I began researching the data science profession, I was instantly intrigued by the blending of hacking skills, statistical expertise and business acumen to solve problems. I knew that my passion for analytics would be a good fit in the data science field. My commitment to making this career transition led me to pursue a graduate degree in data science at UC Berkeley to refine my programming skills and bring me up to speed on current machine learning technologies. My career aspirations are to build complex algorithms to extract insights from data that provide solutions, drive strategy, and add value to organizations and society.
When I am not deeply involved in my machine learning modeling, you might find me working on my other modeling. In my spare time and when given the opportunity, I enjoy modeling in print advertisement campaigns for financial, athletic, and tech companies. On the weekends I try to stay active and can usually be found on a basketball court or running trails around the Bay Area.
Below is my collection of individual and team projects from my two years in the UC Berkeley Master of Information and Data Science program. I have had the privilege to collaborate with some truly exceptional colleagues and advisors that have helped me along this journey.
Ryan Sawasaki
About
DATA SCIENTIST | SAN FRANCISCO


Hyperion SolarNet
A capstone project utilizing deep learning methods for automated detection of solar panel locations and their total surface area using aerial imagery. HyperionSolarNet consists of a two-branch model using an image classifier in tandem with a semantic segmentation model to provide an efficient and scalable method for detecting solar panels with reliable performance. This research project includes an application that provides users with an interactive mapping tool that visualizes the predicted solar panel mask overlay output from the classification and segmentation models.

Reading Comprehension and
Open-Domain Question Answering
with BERT
A natural language processing research paper analyzing the difference between reading comprehension and open-domain question answering. This paper examines two potential factors, context length and question generation, that make open-domain question answering the more difficult task. The Stanford Question Answering Dataset (SQuAD 2.0) is used as the baseline reading comprehension dataset and Google Natural Questions (NQ) as the open-domain dataset. A BERT-base uncased model is fine-tuned on the datasets to run experiments evaluating model performance.
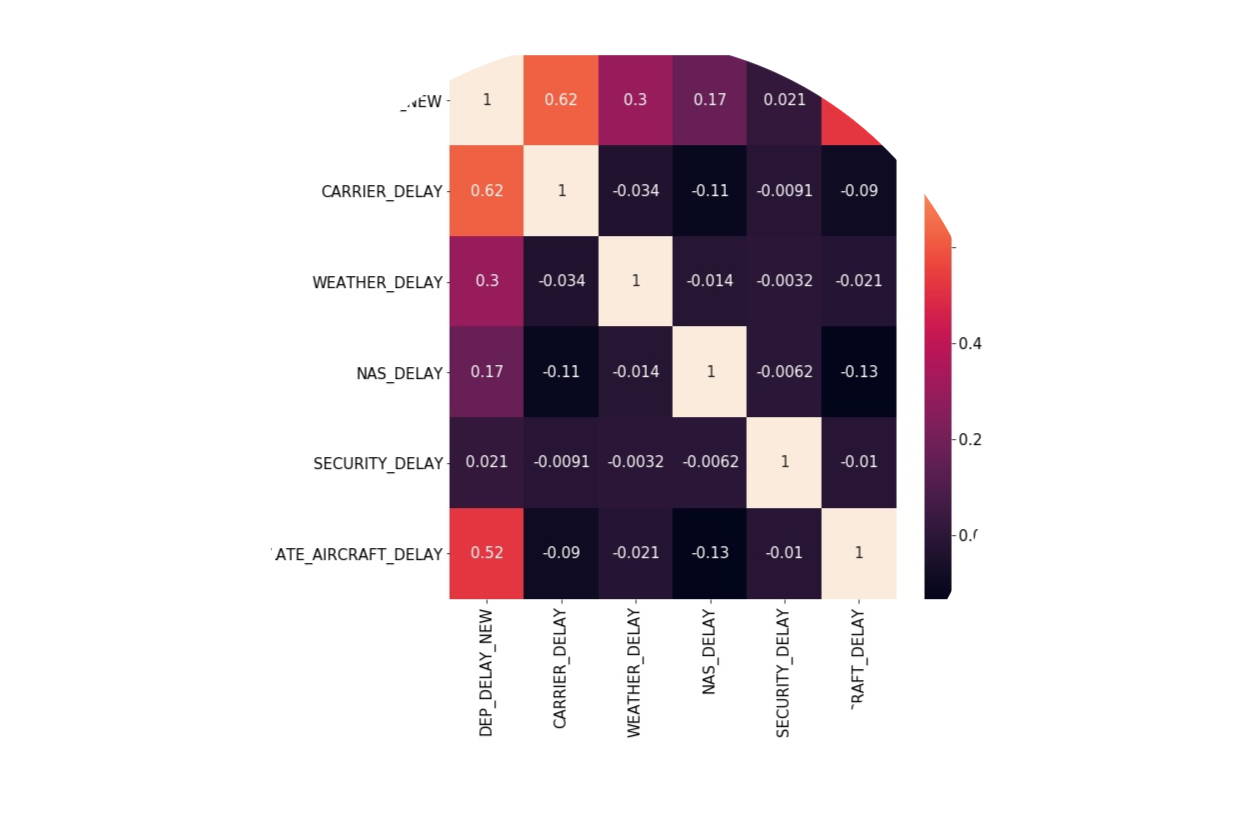
Predicting Flight Departure Delay
A machine learning project predicting flight departure delays using an airlines dataset of 30 million records and weather dataset of 630 million records. Using the Databricks platform, data preparation and feature engineering are performed on the two datasets. Categorical data is indexed, one hot encoded and assembled into vectors along with numerical data. A data pipeline is built in preparation for algorithm exploration. Using Apache Spark’s machine learning library, scalable logistic regression, decision tree, and random forest classification models are conducted.

Effects of Race on Perceptions of Professionalism
A causal inference experiment examining the effects of an individual’s skin tone on how others view their level of professionalism. The project is based on my research experiment proposal that was reviewed by academic peers and selected as one of the top 3 proposals to proceed with execution of the collaborative final experiment. The survey data is collected using Qualtrics and Prolific platforms. An analysis involving hypothesis testing and OLS regression for within-subjects experiment is conducted using R statistical software.
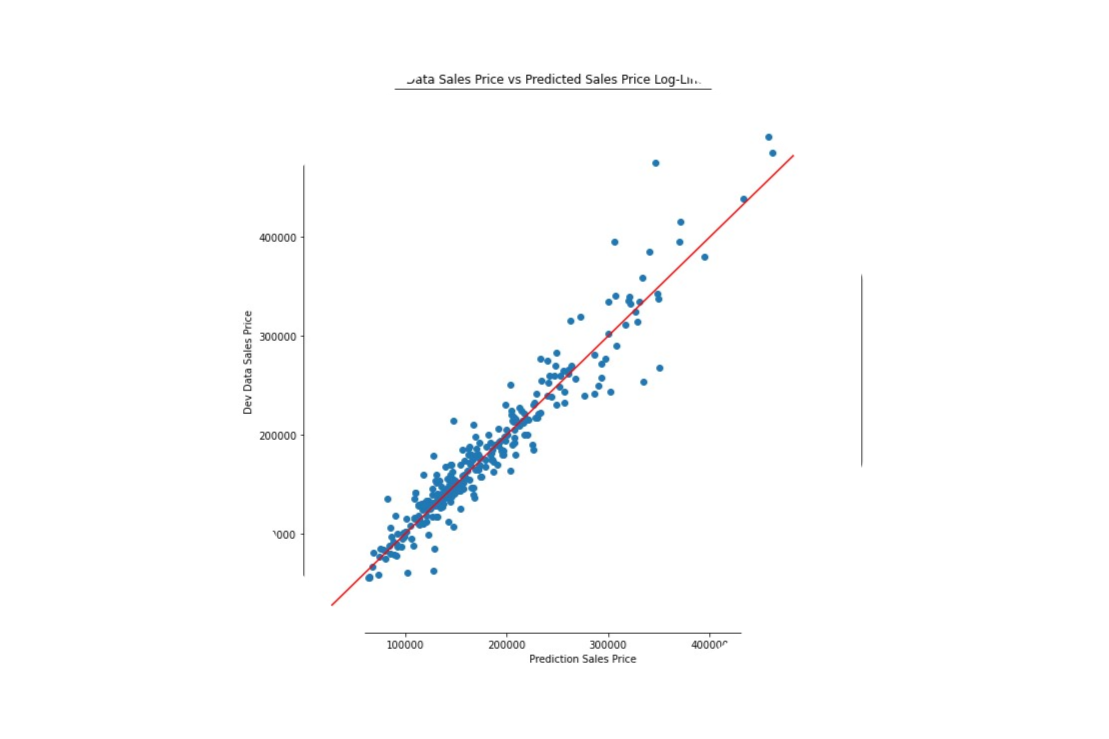
House Price Prediction
A collaborative machine learning project to predict home sale prices using a housing dataset with 80 explanatory variables. Using Python and Jupyter Notebook, the project runs an ensemble of advanced regression techniques including linear regression, decisions trees with gradient boosting and neural networks. My individual contributions include the use of feature selection methods to refine linear regression models resulting in a mean log square error that was a 70% improvement over the baseline model.

Reducing Crime
A collaborative project analyzing a dataset of state crime statistics, which includes a dependent variable of crime rate and independent variables grouped into categories of deterrent, demographic, economic and geographical factors. The key determinants of crime are identified using R statistical software to build regression models to analyze the explanatory variables with practical and statistical significance. The results of the models are used to make policy recommendations directed at reducing crime levels.
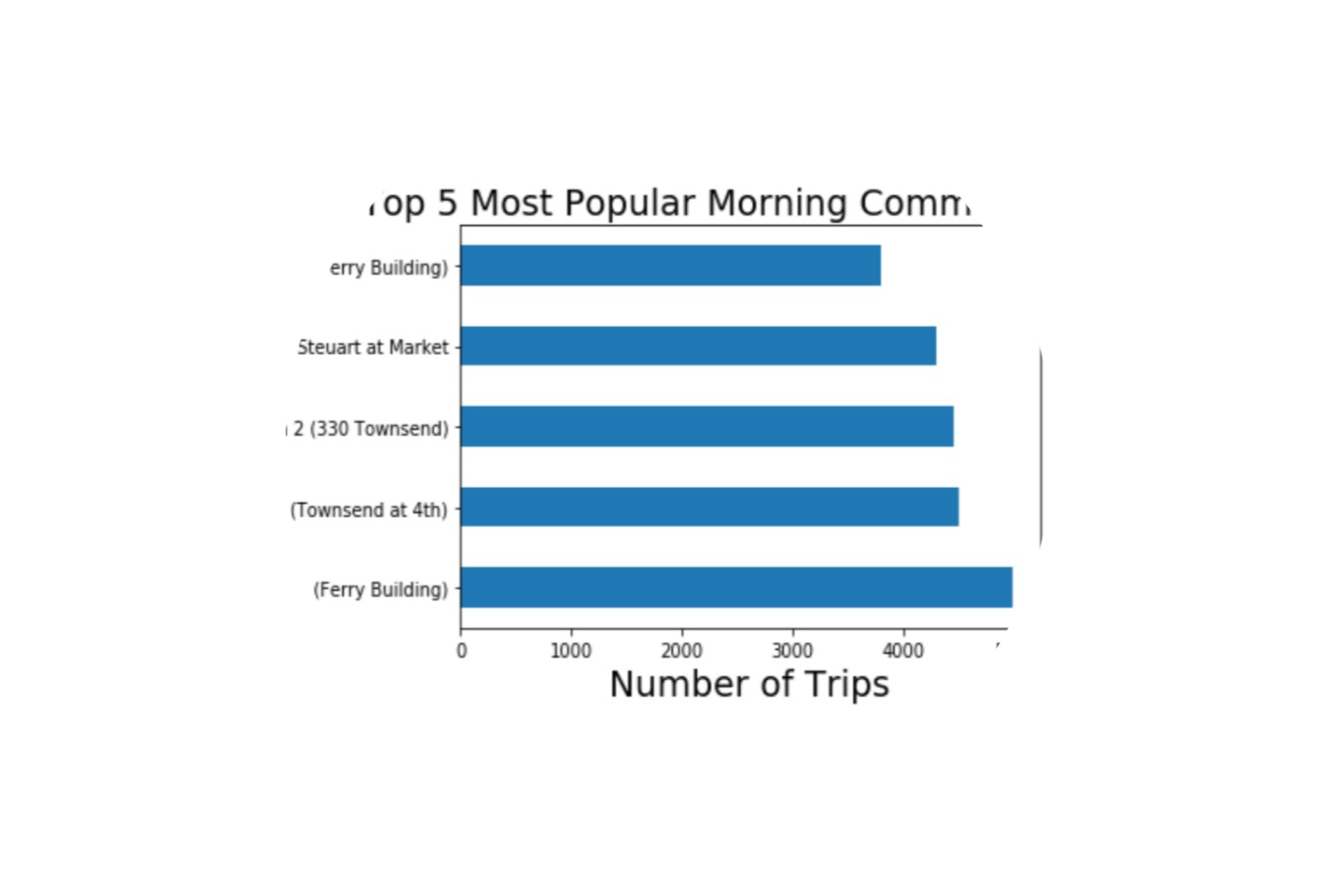
Bike Share Query Project
A query project that uses the Lyft Bay Wheels dataset to gain insight into popular bike share commuter trips within San Francisco. Utilizing SQL and BigQuery within the Google Cloud Platform (GCP), queries are made from a Jupyter Notebook through a virtual machine and presents findings using Pandas output tables and Matplotlib visualizations. The data analysis results are used to answer business-driven questions and provide recommendations to increase ridership.
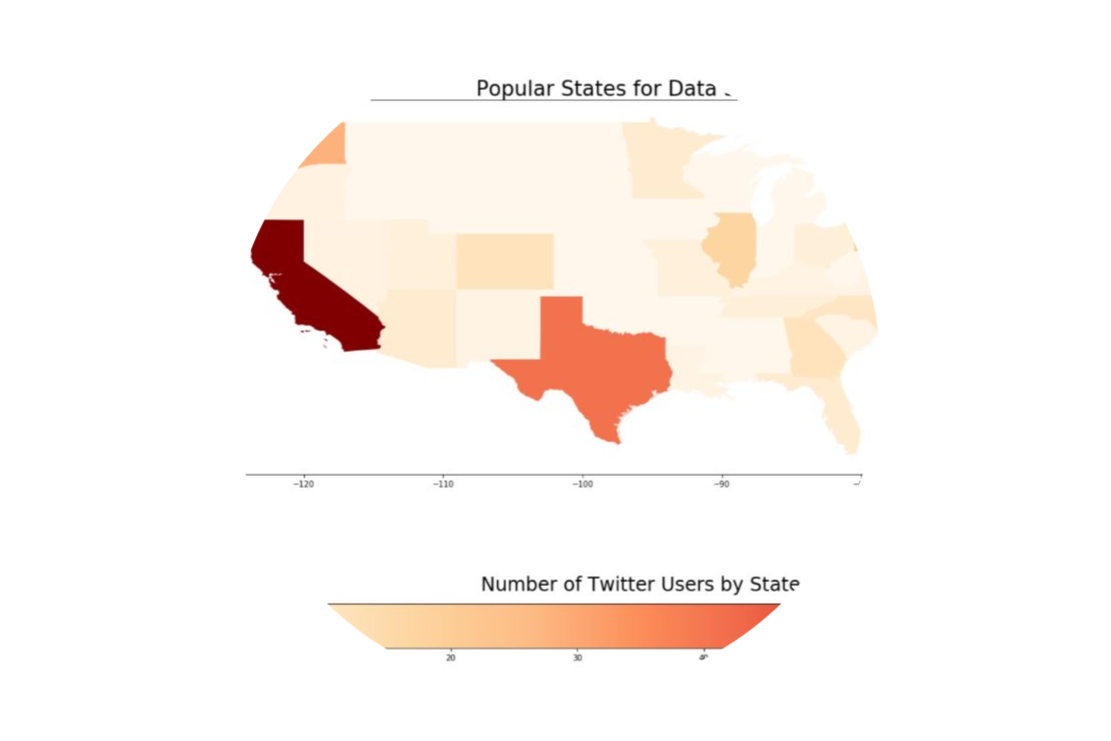
Analyzing Twitter Data for #DataScience
A collaborative Python project conducting a data analysis of Twitter users who include the hashtag #DataScience. The project uses the Tweepy package to access JSON structured data through the Twitter API. Using the Twitter data, an analysis determines the influential users, sentiment, and location of those who use the #DataScience. My individual contributions include an analysis of the location of twitter users with presentation of findings through visualizations using Matplotlib and Geopandas.
Education

University of California, Berkeley
Master of Information and Data Science (MIDS)
Data Science

Stanford University
Master of Science (MS)
Structural Engineering

University of California, Irvine
Bachelor of Science (BS)
Civil Engineering